大模型的竞争越来越激烈,各家大模型厂商也纷纷调低了大模型API的价格。这对于想尝试利用大模型的AI能力来构建AI应用的开发者来说无疑是非常利好的消息。
甚至各家厂商还放出了一些轻量的大模型可以免费调用。
经过测试对比,我给大家推荐两个免费可用的大模型API。
智谱AI
北京智谱华章科技有限智谱AI(简称”智谱AI”)是一家致力于推动人工智能发展的创新型科技智谱AI。作为中国大模型领域的领军企业,智谱AI在认知智能大模型研发
方面取得了显著成就。智谱AI成功研发了中英双语千亿级超大规模预训练模型GLM-130B,并基于此推出了广受欢迎的对话模型ChatGLM系列。其中,开源单卡版模
型ChatGLM-6B的全球下载量已超过800万次,充分展现了其技术实力和影响力。
智谱AI不仅在语言模型方面表现卓越,还在多个AI领域取得了突破性进展。智谱AI开发的代码生成模型CodeGeeX每天协助程序员编写1000万行代码,大大提高了开
发效率。此外,智谱AI还推出了多模态理解模型CogVLM和文生图模型CogView,进一步扩展了AI的应用范围。
智谱AI秉承”Model as a Service”(MaaS)的创新理念,推出了大模型MaaS开放平台,为各行各业提供高效、通用的AI开发解决方案。智谱AI的产品矩阵涵盖了A
I提效助手”智谱清言”等多个创新应用,为用户提供全面的智能化服务。
值得一提的是,智谱AI的ChatGLM3模型在C-Eval榜单上表现出色,展现了智谱AI在大模型研发方面的领先地位。智谱AI最新发布的GLM-4基座大模型更是将整体性能
提升到了世界先进水平,进一步巩固了智谱AI在行业中的重要地位。
作为国内首批通过备案的大模型产品提供商,智谱AI正在为千行百业带来持续创新与变革,加速推动通用人工智能时代的到来。凭借强大的研发实力和广泛的应用
场景,智谱AI正在为中国乃至全球的AI技术进步做出重要贡献。
下面是智谱AI 开放平台提供的最新模型。包括通用大模型、图像大模型、超拟人大模型、向量大模型等多种模型。

今天推荐的就是其中的GLM-4-Flash。GLM-4-Flash不仅支持长度达 128K 的上下文的文本输入,而且吐字速度也是飞快,达到了惊人的 72.14 token/s,约等于每秒 115 个字符,轻松超越全人类最快打字员(一分钟敲807个字符)。
另外,GLM-4-Flash也支持Function Calling,这意味着开发者可以让GLM-4-Flash与真实世界实现更多的交互,比如让GLM-4-Flash和网页搜索结合获取互联网上最新的信息,又比如实现特定的函数让GLM-4-Flash可以获取特定数据库的数据。可以做的事情太多了,就差那你的创意了。
关于Function Calling,我绘制了下面一张图片帮助你理解。
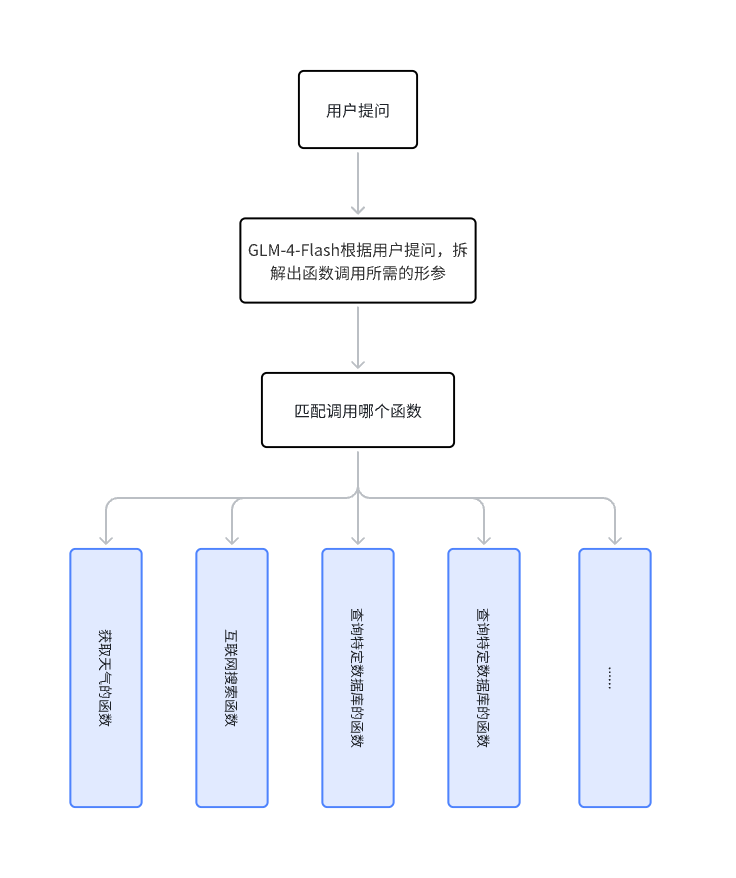
更多相关信息可以访问智谱AI的帮助文档,里面有一篇讲解的非常清楚的文章。
文章链接:https://open.bigmodel.cn/dev/howuse/functioncall
在智谱AI大模型体验中心,你也可以体验智谱AI最新开放的大模型。
可以通过这个链接注册访问:https://www.bigmodel.cn/invite?icode=HHisdLuQOJmZDEA3WxhXtenfet45IvM%2BqDogImfeLyI%3D
下面我们来考验一下GLM-4-Flash。
先上一下,前段时间让很多大模型翻车的数学小数点问题。「9.11 和 9.9 哪个更大」

GLM-4-Flash分析的有理有据,最终快速给出了正确答案。
作为对比,我也测试了一下GPT-4O.

GPT-4O 想了一会,但还是给出了错误答案。
第二道题,我从MBA逻辑推理真题上选了一道题。

GLM-4-Flash的回答很快,也给出了正确答案。但分析的略微简单了。
同样的我们让GPT-4O来试试这个推理问题。

GPT-4O分析的有理有据,并且推理过程详尽。
总结一下,GLM-4-Flash是一个轻量的模型,推理速度更快并且API调用免费。对于一些简单的任务,我们可以使用GLM-4-Flash去处理,这样就节省了AI应用的使用成本。而GPT-4O更贵,推理速度稍微慢一点,但准确率会更高,用于处理更复杂的问题会更好。
另一个点也不得不提一下。GLM-4-Flash支持微调服务。
如果基础模型和现有工具无法完全满足你的需求,特别是在处理复杂推理任务时。这时,微调(fine-tuning)可能是一个值得考虑的选择。
微调能够改善结果的典型场景
- 需要特定的风格或语气
- 当你希望模型输出具有独特的品牌声音或特定的写作风格时
- 需要处理复杂任务
- 对于需要多步骤推理或专业知识的任务,微调可以显著提升模型性能
- 需要提高输出可靠性
- 微调可以帮助减少幻觉(hallucinations),提高答案的准确性和一致性
- 新任务难以通过提示解释
- 当某些任务难以用简单的提示来指导模型完成时,微调可以教会模型理解和执行这些任务
微调的优势
更好的任务适应性
提高特定领域的准确度
个性化的用户体验
潜在的成本节约(通过减少复杂提示的需求)
将满足特定场景需求的数据投喂给GLM-4-Flash,利用智谱AI的微调工具即可轻松微调GLM-4-Flash。对于微调出来的模型, 智谱AI也支持私有部署。
体验链接:https://www.bigmodel.cn/invite?icode=HHisdLuQOJmZDEA3WxhXtenfet45IvM%2BqDogImfeLyI%3D
Google 免费开放的Flash模型
Google 在 Google IO 2024 大会上公布了 Gemini 1.5 Flash model,并且几乎免费地让开发者可以来试用。
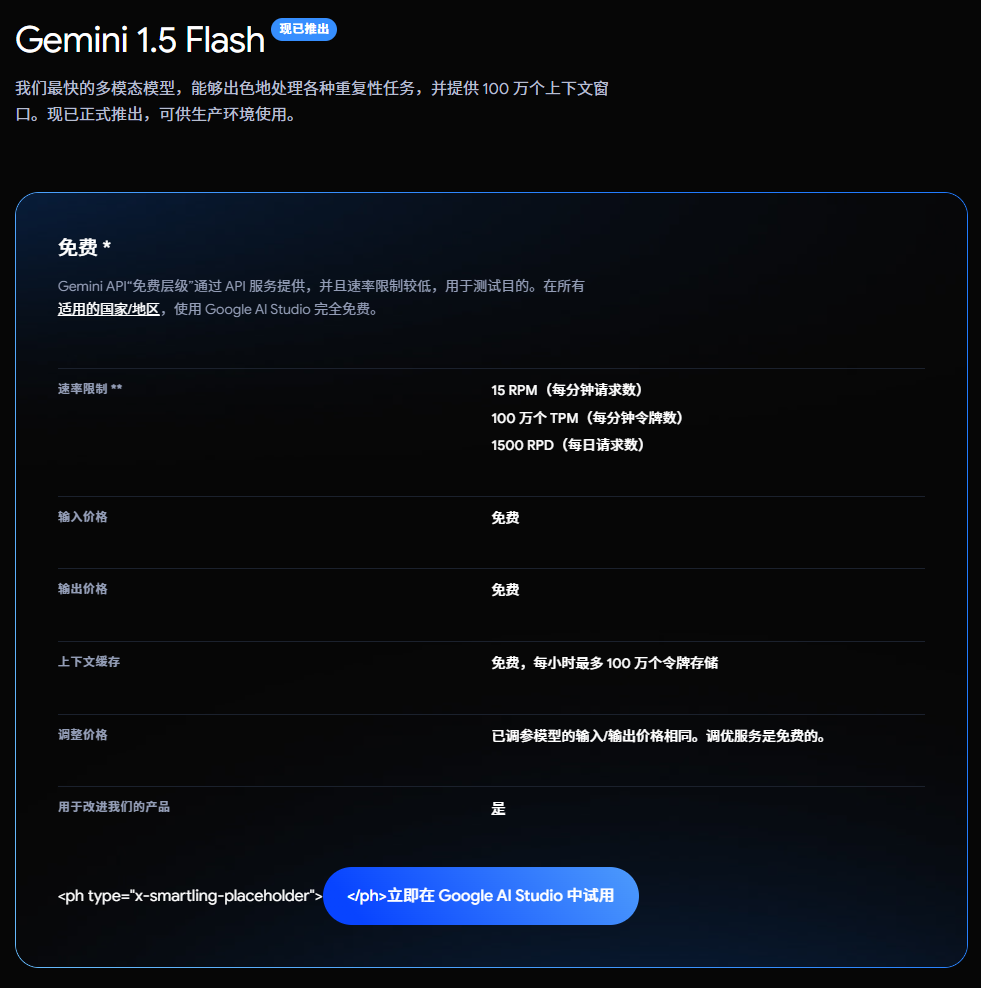
Google 每天为开发者免费提供15亿个Token,其中 Gemini 1.5 Flash免费套餐包含:
每分钟15次请求(RPM)
每分钟100万个Token(TPM)
每天1,500次Token(RPD)
免费上下文缓存服务,每小时最多可存储100万个Token
免费微调 Gemini 1.5 Pro免费套餐包含:
每分钟2次请求(RPM)
每分钟32,000个Token(TPM)
每天50次请求(RPD)
微调模型 text-embedding-004 提供:
- 每分钟1,500次请求(RPM) 除了前面说的 API,Google AI Studio 还为开发者提供免费访问,其中 Gemini 1.5 Pro 有 2M Token上下文窗口。
价格页面:https://ai.google.dev/pricing
Google AI Studio:https://aistudio.google.com
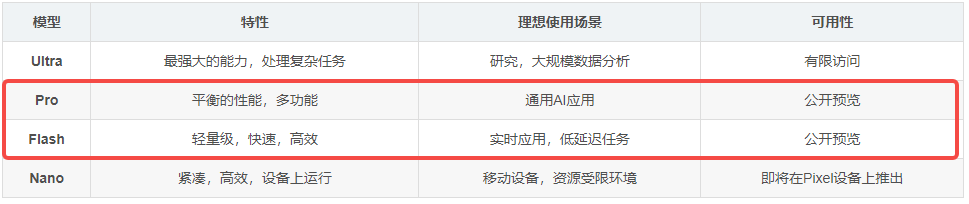
Google官方文章对Gemini 1.5 Pro和Gemini 1.5 Flash的区别做了解释。Gemini 1.5 Pro在一些关键的使用场景中进行了优化,比如翻译,编程,推理等等。从而可以处理更广泛也更复杂的任务。而Gemini 1.5 Flash针对需要高频快速响应的场景进行了优化,比如摘要制作、聊天应用、提供图解,以及从长篇文件和表格中提取数据等任务。
谷歌Gemini模型的概览
Gemini 1.5 Flash 原生支持多模态输入,这意味着你可以直接发送文本、图像、音频和视频给Gemini 1.5 Flash并与其交互。这一点是GLM-4-Flash尚不具备的。
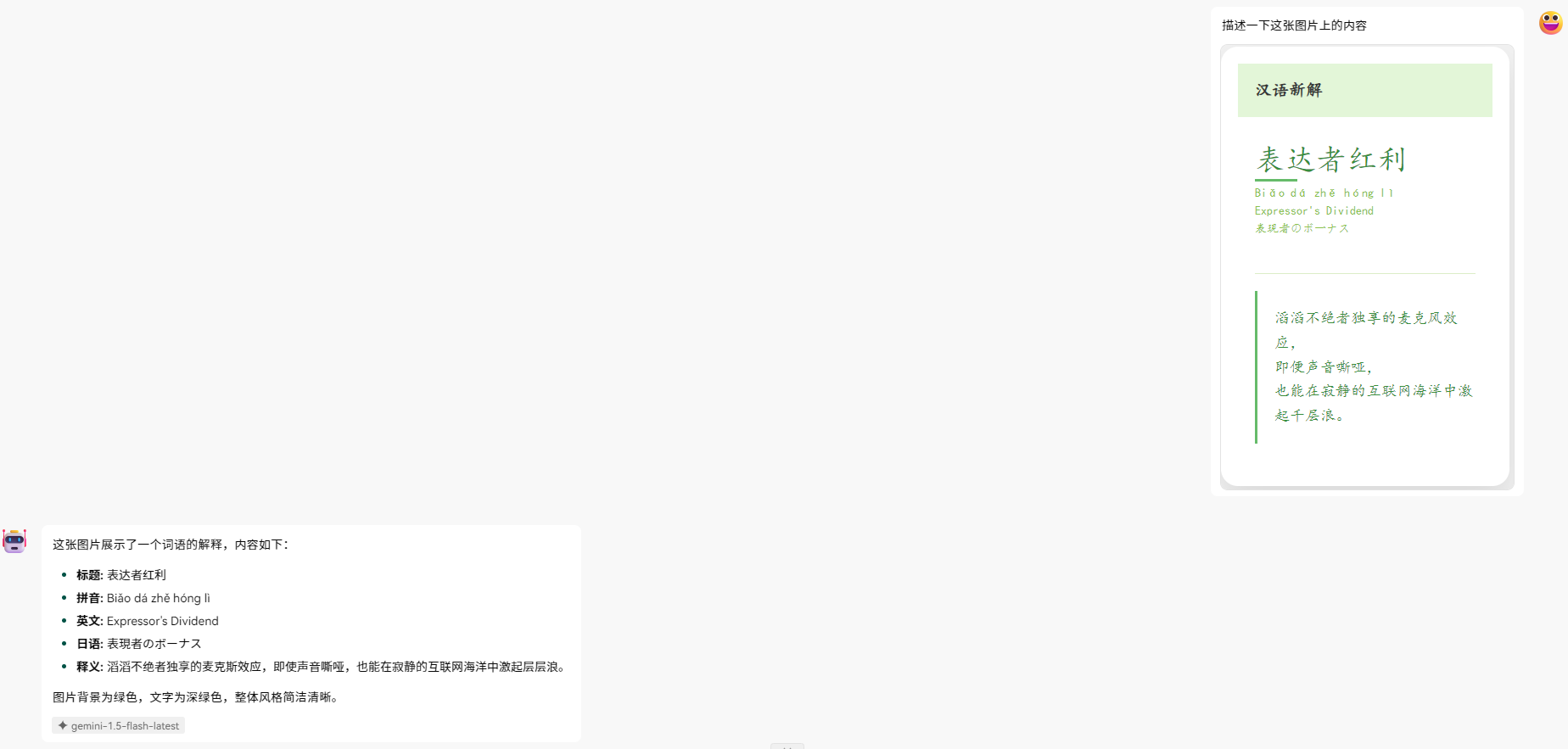
我简单用汉语新解提示词生成的图片给Gemini 1.5 Flash发送过去。它识别的丝毫不差,可以把牛逼打在公屏上了。这可是API调用的效果。这意味着可以近乎免费地使用Google提供的这项服务。
另外,Gemini 1.5 Flash支持结构化输出了。可以以json格式输出回答。你可以在**https://aistudio.google.com/**中体验这项功能。通过结构化输出,可以让回答更稳定,同时回答的文本更容易被提取。
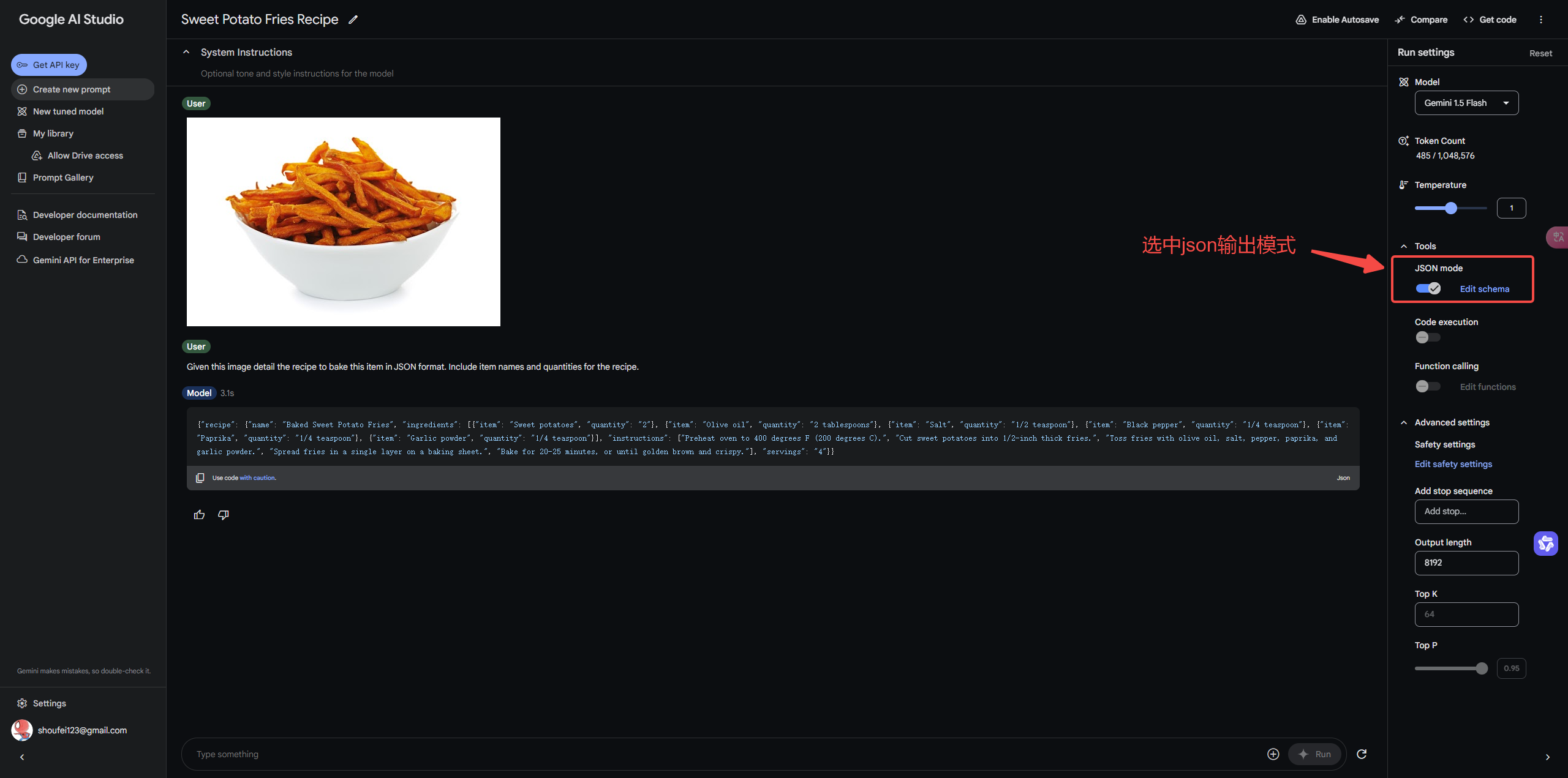
我们也顺便测试一下上面测试GLM-4-Flash的两个问题,看看效果。
首先是,「9.11 和 9.9 哪个更大」

Gemini 1.5 Flash的回答简洁直接并且正确。
下面来测试一下这道MBA逻辑推理真题。

Gemini 1.5 Flash的回答同样没有GPT-4O那么详细的推理过程但反应迅速,回答言简意赅,答案也给正确了。
总结一下
GLM-4-Flash和Gemini 1.5 Flash都是可以免费调用的大模型API。如果你可以用魔法上网当然优先推荐使用Gemini 1.5 Flash,它功能更加强大,支持更多上下文输入(1百万tokens),准确度更高,并且支持多模态输入。